

🙏 Image and research source: Thomas Taylor (GitHub)
If you want to see what an LLM is really good at (and where it still slips), don’t ask it to write a poem or generate code. Ask it to make the same small decision again and again under clear rules.
That is why blackjack basic strategy is such a useful lens.
Basic strategy is basically a decision table. Given your hand and the dealer’s upcard, there is a best move for a given rule set. Hit, stand, double, split, surrender. It is not a vibe. It is a lookup problem.
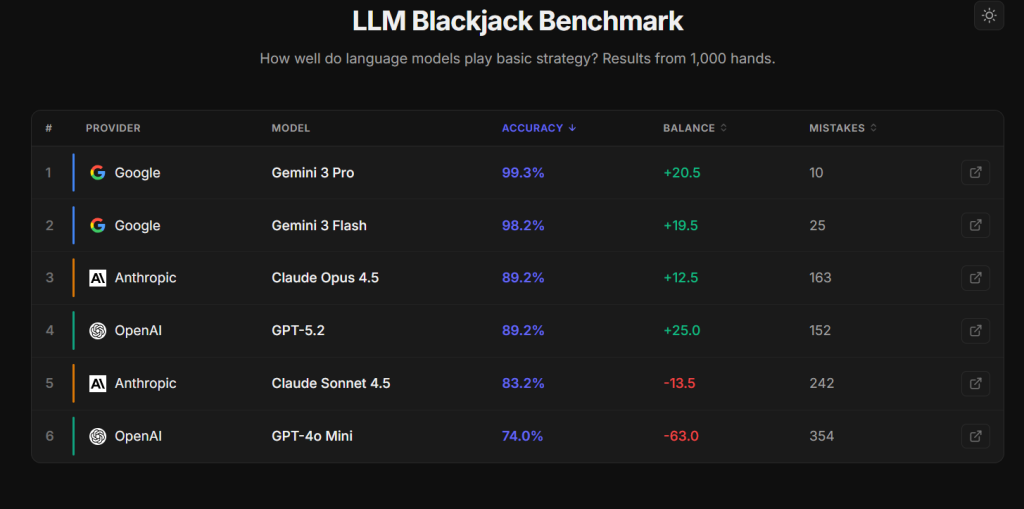
So you would expect modern models to nail it. And some do. But what makes this benchmark interesting is not “who got the highest score.” It is how the models fail.
The result that matters is not the winner, it is the pattern of mistakes
⚡ Check out Thomas’ Page: https://thomasgtaylor.com/blackjack/
When models get decisions wrong in blackjack, they do not usually fail randomly. They tend to develop a consistent style of mistakes.
One model might double too often. Another might be overly cautious and miss good doubles. Another might surrender in spots where it should fight on. That is a big deal because it mirrors what many developers see in real products: the model is mostly reliable, but it has a few recurring blind spots.
This is the key point for builders. LLMs do not fail like buggy programs. They fail like inconsistent policies.
Accuracy and outcomes are not the same thing
The benchmark tracks two things that people often confuse:
- decision accuracy: did the model pick the basic strategy move?
- outcome: did the bankroll go up or down over the run?
These can diverge. Blackjack has asymmetric payouts. A single bad double can hurt more than a small hit/stand mistake. And over a limited number of hands, luck still matters. So you can see a model that is slightly less accurate end up with a better balance simply because variance went its way.
This is not just gambling trivia. It is a reminder that your evaluation metric shapes what looks “best.” If your product cares about costly failures, you should measure cost-weighted errors, not just raw accuracy.
Why this matters outside blackjack
A blackjack hand is a tiny state with a clear action set. Software is full of the same structure:
- incident triage rules
- retry and backoff policies
- access control and permissions
- billing and pricing logic
- feature rollout rules
- compliance checks
In all of these, you often have clear policies you want followed. If a model struggles to consistently follow a small decision table, it will also drift when it is asked to follow your company’s rules unless you design around that.
The better mental model: LLMs behave like learned heuristics
A traditional program executes rules. A plain LLM often imitates rules and sometimes improvises. That is why you see those “error personalities.” The model is not just retrieving the correct table cell every time. It is applying a learned pattern that is usually right, and occasionally biased.
This is the important angle for the Finxter community: treat the model like a policy learner, not a calculator.
What to do with this insight
The engineering move is not to argue with the model harder. It is to change the shape of the task so the model cannot drift.
A few practical approaches:
- Put the strategy table in code and have the model call it.
- If you keep it in the prompt, force a structured lookup format and validate the output.
- Log mistakes by category (too many doubles, early surrenders, split errors) because that tells you what to fix.
A simple Finxter challenge you can copy
The real win here is not blackjack itself. It is the idea of a small, repeatable benchmark.
Pick any domain where ground truth exists as a clear set of rules or a decision table. Generate a lot of reproducible test cases. Score both accuracy and cost-weighted outcomes. Then look for recurring error patterns, not just the overall score.
That gives you something far more useful than “model A feels smarter than model B.” It tells you how a model behaves under repetition, which is what matters when you are building real systems.
✨ Join the Finxter AI Newsletter to be on the right side of change – with 130k readers!